搜索引擎基本原理分析(百度搜索引擎工作原理是什么)
- 作者:小小课堂网 - 阅 1,805 推荐搜索引擎基本原理分析篇。搜索引擎工作原理是非常复杂的,作为SEOer了解基本过程即可,深究可以去详细查阅信息检索技术,有很多数学公式哦。
今天,小小课堂网( xxkt.org.cn )带来的是《搜索引擎基本原理分析(百度搜索引擎工作原理是什么)》。希望对大家有所帮助。

搜索引擎系统是世界上最复杂的系统之一,正常人基本上也是无法掌握所有搜索引擎的所有工作原理中的细节部分,错误君认为对于我们SEOer而言,只需要大致了解搜索引擎的工作原理即可。有兴趣的可以更多研究信息检索技术,可以帮助我们更加深入理解搜索引擎。
本小节错误君主要介绍搜索引擎的工作原理中一些组件:文本采集、文本转换、索引创建、用户交互、索引排序、评价与调整。这六个组件可以归纳为两个环节,一是索引处理,二是查询处理。
索引处理包括:文本采集、文本转换和索引创建。
查询处理包括:用户交互、索引排序、评价与调整。
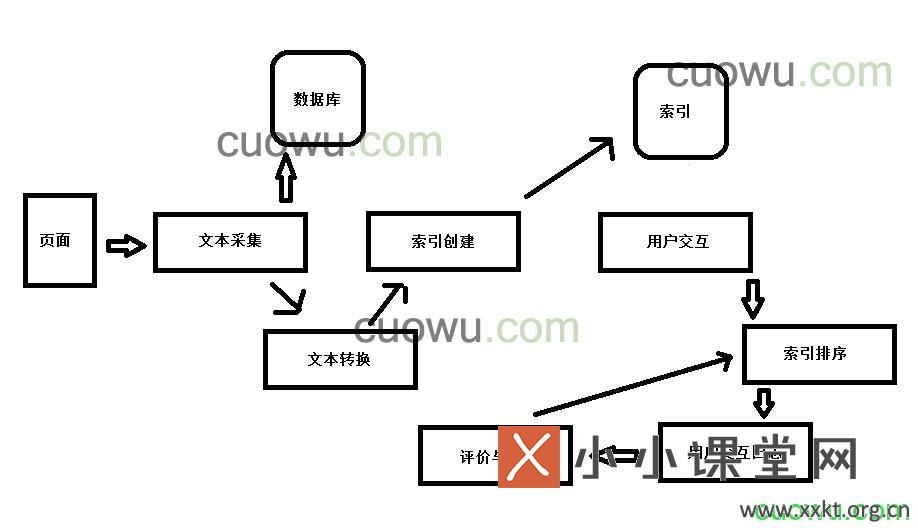
文本采集
搜索引擎的文本采集组件的主要任务为发现文档,并让这些文档能够被搜索到。一方面搜索引擎数据库中已经拥有着极为庞大的页面数量,另外一方面文本采集组件在互联网非常忙碌地进行着爬行,只为收录更全面,内容时效性更强。
搜索引擎的文本采集组件传递采集信息给索引处理组件的同时,还需要将采集的数据放入文档数据库中,在数据存放的之前还应该对文档完成转化,将其转化为索引项,便于后期查询并调用文档。
搜索引擎系统利用网络爬虫可以沿着互联网的页面中包含的超链接进行爬行并发现新的页面。
如果页面已经被收录且页面内容无任何变化,则不会采取任何行为;
如果页面已经被收录且页面内容发生了变化,则会重新对该页面进行收录;
如果页面未被收录且页面达到了收录的标准(如页面质量和内容重复度),则会对页面进行收录,若未达到,则不会收录。
1)爬虫
爬虫,全名为网络爬虫,又被称之为“网页蜘蛛”或“网络机器人”或“页面追逐者”,百度搜索称之为“百度蜘蛛(spider)”,谷歌搜索称之为“谷歌机器人(robot)”。搜索引擎系统中的爬虫组件主要作用是用来发现新页面、抓取并存储新页面至搜索引擎的数据库中。对于SEOer来而言,我们做的大部分事情都是了解爬虫喜欢什么样的网站,然后做成爬虫喜欢的样子,也就是遵循搜索引擎的规则去调整网站,这样做往往对用户也是非常友好的,当然如果某项行为只为了爬虫喜欢而损害真实用户友好度的话,这种调整宁可不做,我们最终是面对用户,而非爬虫。这里所谓的调整一般是为了简化爬虫的工作量,网站简洁的设计更利于爬虫的爬行,减少蜘蛛陷阱等影响爬虫正常爬行的页面设计。
2)信息源
文档信息源是一种存取实时文档的机制。比如现在大部分的新闻源网站都是搜索引擎选择出来的优质网站,通常站点提供的内容均比较优质、时效性较高和更新频率较高。通常情况下,RSS信息源就是这样一个获取资源,像WordPress博客等程序都是提供这样的RSS信息源的,RSS是互联网上信息源采用的一个通用标准,采用标准的XML数据格式,不过一般来讲这个适合用户阅读。搜索引擎一般都是站长主动提供XML网站地图(sitemap)的形式更为实用。
3)转化
搜索引擎转化主要存在有种,一种是网站编码的转化,一种是统一文档格式的和文档元数据格式。
网站编码的转化:国内而言通常采用GB2312(国内标准)或UTF-8(国际标准)的字符编码规范,通常来讲,现在大部分国内网站即便没有外贸也习惯性采用UTF-8,当然在国内网站还是可以使用GB2312的,这两种代码无论哪一种对SEO都是没有影响的。
转化格式:因为爬虫遇到的链接可能是一个HTML页面,也可能是一个XML地图,还可能是用户的一个word附件等等,搜索引擎需要将这些组件都转化成为统一的文档格式和文档的元数据格式。在转化的过程中对部分非内容数据删减,同时提取出并记录元数据。
4)文档数据库
搜索引擎文档数据库用于存储并管理大量文档与这些文档相关的结构化数据,网络爬虫抓取来的数据都需要存放到这里,我们平时看到的快照数据也都是存储到这个数据库中了。为了保证效率,对文档内容通常进行压缩处理。为了保证对大规模数据进行快速检索,通常对文档进行结构化数据处理并建立关系数据库系统,用来存储文档和元数据。除之之外,还需要提取一些搜索引擎需要的信息,比如用于链接原理的页面中存在的超级链接的文本,即锚文本链接中的文字。
文本转换
1)解析器
搜索引擎中的解析组件负责处理文档中的文本词素序列,以识别文档中的结构化元素,如标题、图标、超级链接等等。词素切分让文档或查询词都变为词素,如“SEO”和“SEO优化”均为词素,很多时候,词素和词是等同的。那有的时候就需要根据文档中其他词素来确定某些词素的意思,比如说“苹果”,如果文档中多处出现产品、口感、水果等词,则这个苹果指的就是我们日常吃的一种水果,但如果文档中多处出现iPhone、苹果公司、IOS等词,则这个苹果是指苹果公司推出的智能手机。
文档结构由HTML、XML等标记语言来指定。HTML指定网页结构,XML用于数据交互格式。文档解析器主要依靠标记语言的语法来识别文档的结构。比如HTML中的a标签代表超级链接,<a href=””></a>。
2)停止词去除
停止词去除组件的任务是从那些成为索引项的词素序列中删除常用词。这些常用词是一些典型的功能词,这些功能词有助于构成句子的结构,让句子更加通顺。比如英文的“to”、“of”、“the”等,中文的“的”、“得”、“地”。但是他们也不能完全去除这些词,还需要根据具体的语义,比如“to be or not to be”就不能被去除,比如“中华大地”中的地也不能被去除。
3)词干提取
词干提取在中文搜索中基本不使用,因为汉语变化少,提取也没用。但英文或其他语言则会不同,比如鱼的英文为fish,那么词干就是fish,其扩展词有多条鱼fishes、钓鱼中fishing等等。
4)超链接的提取与分析
链接算法有很多比如李彦宏的超链分析、谷歌的Google PR、搜狗的SR、HTIS算法、Hilltop算法、TruskRank算法等。搜索引擎中有关超链接的提取和分析是非常重要的,在对文档进行解析的过程中,页面中的超级链接及其对应的锚文本可以被很轻松地提取出来,作为索引排序的重要数据。当然这里的超链接指外部链接,也指网站内部链接。
那么这里错误君提一句纯文本链接和锚文本链接,如果是锚文本链接那么这种对应关系就可以被提取并储存,但是如果是纯文本链接就不会有这种效果了,但如果页面内容与纯文本链接网址具有一定相关性,那么也会对排名有一定好处,但是一定不如锚文本链接效果好,毕竟锚文本链接是清清楚楚告诉了搜索引擎这个链接对应的关键词,但是纯文本却没有。PS:图片链接中的alt等同于锚文本链接中的文字,但是效果相对弱一些。
5)信息的提取
信息的提取用于识别更加复杂的索引项,并非是一个单独的词。这些索引词可以看成是一个黑体、加粗的词,也可能是标题中出现的词,但往往需要一些计算。信息提取中通常采用某种形式的语法分析和词性标注等特征。例如,一篇关于地名的文章,可能出现识别的是哪个省、哪个市、哪个区、发布日期、发布人姓名等等。
6)分类组件
搜索引擎中的分类组件可以将文档或文档中的部分内容识别出类别相关的元数据。比如分成“经济”、“科学”、“商业”等,这种分类需要判别文档是否为垃圾文档以及识别文档中的非内容部分,如识别文档中的广告。
索引创建
1)文档统计
搜索引擎文档组件用于统计简单汇总和记录词、特征和文档的统计信息。排序组件使用该信息来计算文档的分值。通常所需要的数据包括索引项在各文档中出现的次数、索引项在文档中出现的位置、索引项在一组文档中出现的次数,以及按照词素数量统计的文档长度。真正所需要的数据是由检索模型和排序算法来决定的。文档统计结果存储在查找表中,查找表是设计用于快速检索的一种数据结构。
2)加权-正向索引
索引项的权值反应了文档中词的相对重要性,并且用于为排序计算分值。权值的形式是由检索模型来确定的。搜索引擎加权组件利用文档统计结果计算权值,并将权值存储在查找表中。权值的计算可以是查询处理的一部分,并且一些类型的权值需要关于查询的信息,但一般情况下搜索引擎都会在索引过程中尽可能多的计算,这样就可以减少在查询处理中的计算,从而提升查询处理的效率。
在检索模型中,最普通使用的一种加权方法称之为“tf-idf”。基于索引项在一个文档中的次数或频率以及索引项在整个文档集合中出现的频率两者的组合。索引项出现次数越多越好,索引项在整个文档集合中出现的越少越好。实际应用就是增加页面的关键词密度和频率但不能过度堆砌,搜索引擎搜索相关结果数量越小是判断这个词优化难度较低的原则之一。
3)倒排索引
倒排组件是搜索引擎索引处理的核心组件。原本我们做的索引都是文档对应多个索引项,倒排索引组件是将这些数据变成了索引项对应多个文档。高效完成倒排索引也是搜索引擎面临的挑战之一,除了在索引创建时就需要处理大量的文旦,在爬虫或信息源获得新的文档时索引还应该可以被几十更新。倒排索引的设计用于快速的查询处理,并且在一定程度上依赖于所采用的排序算法。索引还会被压缩处理以便进一步提升效率。
4)索引分派
索引分派组件将索引分发多台计算机,这些计算机可能是网络中的多个站点,这种分布式处理是搜索引擎效率的基础,同时可以降低其他节点出现问题导致的时延。
用户交互
1)查询输入
查询输入组件为查询语言提供了接口和解析器,在用户输入并搜索之后,对该查询内容进行解析,也可以理解为进行分词处理。在大多数网络搜索接口中使用的最简单的查询语言仅有少量的操作符。操作符是查询语言的命令,用于指示文本需要进行特殊方式的处理。通常,搜索引擎会限制文档中的文本与查询中的文本如何匹配,有助于使用用户查询的意义更加清晰。
例如,一个简单的查询语句中使用了引号操作符,是指引号内的词必须作为一个完整匹配的形式出现,这里就说的搜索引擎高级搜索中的引号的作用。然而,在普通用户查询中往往没人使用这种操作符,关键词如果是一个简单的词,那么对于指定查询的话题就会比较容易和精准。比如查询“SEO”和“错误教程的SEO知识怎么样”相比,搜索引擎可以给出SEO比错误教程的SEO知识怎么样更为精准的答案。
2)查询转化
查询转化包括的内容很多,比如之前说过的分词技术、停止词的去除和词干的提取等等,然后生成可以查询的索引词。这些技术用于生成排好序的文档之前和之后改善初始查询。
拼写检查和查询建议是查询转换中的技术,生成与用户初始查询相似的输出。
拼写检查:拼写检查是为了纠正拼写错误或对用户所需信息提供更加规范的描述。如平时我们常见到的搜索引擎努力纠正拼写错误的词汇。比如“博人转”会自动显示“博人传”,输入拼音“cuowu”,通常会显示“错误”的相关搜索,而不是“错悟”。
查询建议:查询建议是一种查询扩展技术,给出用户一些相关建议,比如搜索引擎下拉词和相关搜索词的出现。
3)结果输出
结果输出组件负责对相关组件得到的排好序的文档结果进行显示。其任务有生成页面摘要(如果没有页面描述或页面描述中不包含用户搜索词时),强调文档中的重要的词(比如百度搜索一般将结果页面中出现的搜索词都会变成红色),是否生成图片、子链等等展现形式。
索引排序
1)查询处理
查询处理组件会在检索模型的基础上,采用排序算法来计算这些文档的分值,也等于是第二次加权处理。这里的索引排序算法就是我们平时听到的那些了,比如百度的绿萝算法、Google的企鹅算法等等。
2)性能优化
优化索引排序算法和索引表的设计,可以降低系统响应的时间,从而提升查询的吞吐量。
3)分布式
既然索引可以分布的给出,那么排序也是可以分布式给出的,也是提升的效率,节省了时间。
评价与调整
1)日志
搜索引擎的点击日志是调整和改善搜索引擎系统效果和效率的非常有价值的信息源,通过用户查询与搜索引擎交互的信息可以调整搜索算法的不足。就明显的就是SEOer常说的提升用户友好度,方法就是提高用户在网站的驻留时间和点击数据,时间和数量越大,说明这个网站的用户友好度就越高,提升这样的页面的排名,有利于提升搜索友好度,对搜索引擎也是有着极大好处的。
搜索引擎评价体系非常重要,相关性的研究仅仅是最初的筛选和排序,但是否是用户真正期望的,还需要通过评价体系来完成。搜索引擎评价系统很大程度上依靠的是这些日志数据。
用户点击生成的日志数据:搜索引擎可以将用户点击的数据在后台记录下来,生成大量的日志数据,再利用这些数据对搜索引擎进行评价。
搜索引擎评价方法:其中一种为Cyril Cleverdon的评价方法。评价中有两种指标:准确率和召回率。准确率,是指检索出来的文档中相关文档所占比例。召回率,是指全部文档中中被检测出来的文档比例。
2)排序分析
拥有了日志之后,就需要对现有排序进行分析了,比如给予初始排名比较高的页面却没有点击,或者又点击跳出率却非常高,降低这类页面的排名,对于翻了几页后,点击多且用户表现出来的行为非常好的情况,会提升这类页面的排名,当然,这种页面很多的话,也会对整站排名有着非常好的作用。
3)性能分析
性能分析则是对搜索响应、吞吐量、网络各个节点的使用情况进行分析,从而更好地优化搜索引擎的性能。
以上就是小小课堂网( xxkt.org.cn )带来的是《搜索引擎基本原理分析(百度搜索引擎工作原理是什么)》。感谢您的阅读。
本文最后一次更新时间:2022年2月28日
随机文章
seo推广教程
WordPress网站更换域名教程(WordPress网站更换域名详细教程)
南通seo培训(网站运营管理)
域名发现对于安全测试意义(域名发现对渗透测试作用)
如何让关键词快速上首页(网站首页的关键词怎么写)
小小课堂SEO培训(百度小故事资质审核和对接流程)
小小课堂SEO培训(百度移动搜索规则)
百度降权的原因(网站降权的原因如何知道)
本文《搜索引擎基本原理分析(百度搜索引擎工作原理是什么)》由小小课堂网整理或原创,侵删,欢迎转载并保留版权:https://xxkt.org.cn/ 感谢您的阅读。








